著作转载开始:YangzuG环球现金网
最近传言称,某知名皇冠进行大额赌博,引起不小轰动。微软念念要强调的,亦然 Gemini 发布时就已流露出来的,是两个模子的性能其实是至极的。 图片开始:由无界 AI生成
图片开始:由无界 AI生成险些不讲武德,继上周推出堪称其“最新、功能最无边”的 AI 模子 Gemini 后,当天,谷歌告示将向征战东说念主员和组织提供 Gemini Pro 以及一系列新的东说念主工智能器具、模子和基础架构。
皇冠信用登录网址源头,Gemini Pro 可通过 Gemini API 提供给 Google AI Studio(免费的基于 Web 的征战器具)的征战东说念主员。企业也不错通过谷歌云的 Vertex AI 平台进哄骗用。此外,谷歌还将在 Vertex AI 中引入其他模子,匡助征战者和企业活泼构建和发布应用弊端,包括升级版的文生图器具 Imagen 2,以及针对医疗保健行业微调的基础模子系列 MedLM。另外,谷歌还告示其面向征战东说念主员的在线联接器具 Duet AI 已全面上线。
手脚对 OpenAI GPT-4 的复兴,谷歌 DeepMind 称,Gemini 的 Ultra 版块在 32 项步履性能方针中,有 30 项方针王人优于 GPT-4。
比特币的可拓展性问题往往与区块链价值主张相结合uG环球现金网,因此不能通过改变区块链中的参数来简单地增强可拓展性。比特币社区主要可以调整两个变量来尝试增加每秒事物处理数量(TPS)。一个变量是区块大小,另一个变量是区块生成时间。
关联词,发布还不到一天,Gemini 就遭到了质疑,不仅测试步履有失偏颇,连成果视频也疑似编订。
www.viphuangguantiyuservice.vip无独到偶,微软当天发文更是把谷歌的脸打的啪啪响。微软称,GPT-4 与非凡的辅导政策相结合,在话语默契基准 MMLU(预计大领域多任务话语默契才调)中的进展优于谷歌 Gemini Ultra。
微软的反击:复杂辅导训诲基准性能
据悉uG环球现金网,Medprompt 是微软最近推出的一种辅导政策,最初是针对医疗挑战而征战的。不外,微软的商量东说念主员发现,它也适用于更无为的应用。
通过使用矫正版的 Medprompt 运行 GPT-4,微软在 MMLU 基准测试中赢得了新的本事水平 (SoTA) 分数。把柄施展,皇冠分红GPT-4 在 MMLU 中的进展达到了 90.10% 的历史新高,杰出了 Gemini Ultra 的 90.04%。
2022皇冠足球源码注:MMLU 基准测试是一项知识和推理的轮廓测试。它包含数学、历史、法律、估量机科学、工程和医学等 57 个学科领域的数万个题目。它被合计是话语模子最进军的基准。
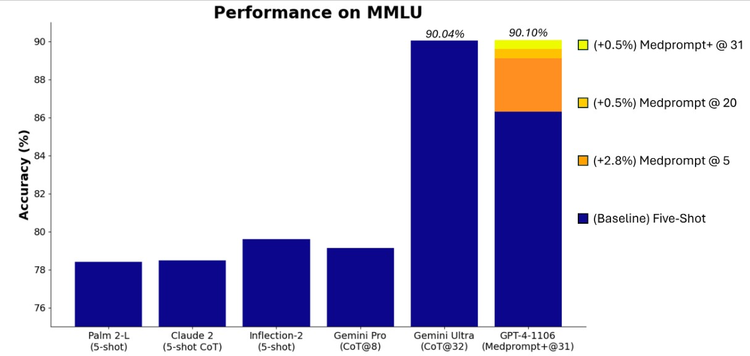
据悉,最初将原始 Medprompt 应用于 GPT-4 在轮廓 MMLU 上的得分率为 89.1%。而通过将 Medprompt 中的麇集调用次数从 5 次加多到 20 次,GPT-4 在 MMLU 上的进展进一步训诲到 89.56%。为了达到新的 SoTA,微软的商量东说念主员将 Medprompt 延长为 Medprompt+,时势是在 Medprompt 中添加一种更浮浅的辅导时势,并制定一种政策,将 Medprompt 基本政策和更浮浅的辅导时势的谜底结合起来,得出最终谜底。
皇冠hg86a
除了 MMLU 基准测试以外,微软还发布了其他基准测试的适度,使用这些基准测试中常见的浮浅辅导来自满 GPT-4 与 Gemini Ultra 的性能比拟。据称,GPT-4 在使用这种测量时势的多个基准测试中进展均优于 Gemini Ultra,包括 GSM8K、MATH、HumanEval、BIG-Bench-Hard、DROP 和 HellaSwag。
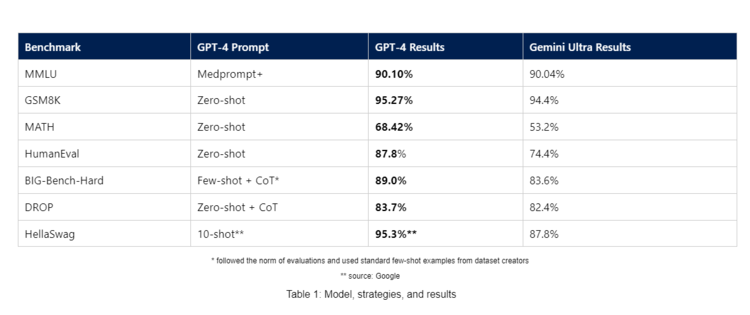
微软暗示,诚然系统化的辅导工程不错产生最高性能,但其仍在探索使用浮浅辅导的前沿模子开箱即用性能。微软称,进军的是,要关心 GPT-4 的原生功能,以及若何利用零次或一丝辅导政策迷惑模子。如上图所示,在接管更复杂、更不菲的时势之前,简陋单的辅导驱动有助于确立基线性能。
据悉,微软已在名为 Promptbase 的 GitHub 中发布了 Medprompt 和访佛的辅导政策,包含剧本、通用器具和信息,可匡助重现上述测试适度。
体育彩票实时需要属意的是,在本体应用中,这些基准中的微弱相反可能不会有太大影响,毕竟它的目标是用来公关的。微软念念要强调的,亦然在 Gemini Ultra 发布时就依然流露出来的,是两个模子的性能其实是至极的。
皇冠比分可能正如比尔·盖茨最近所说的那样,现时面孔的 LLM 本事依然达到了极限。大纲领比及 GPT-4.5 或 GPT-5 的出现,才有可能迎来下一波波浪。
参考连气儿: ]article_adlist-->https://the-decoder.com/microsoft-puts-gpt-4-ahead-of-gemini-ultra-again-using-googles-own-tricks/https://www.microsoft.com/en-us/research/blog/steering-at-the-frontier-extending-the-power-of-prompting/]article_adlist-->平博轮盘在线博彩平台投注
]article_adlist-->https://the-decoder.com/microsoft-puts-gpt-4-ahead-of-gemini-ultra-again-using-googles-own-tricks/https://www.microsoft.com/en-us/research/blog/steering-at-the-frontier-extending-the-power-of-prompting/]article_adlist-->平博轮盘在线博彩平台投注皇冠客服飞机:@seo3687uG环球现金网
线上菠菜平台 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP